


PHÂN TÍCH NHÂN TỐ KHÁM PHÁ EFA
Phân tích nhân tố là phương pháp thống kê được sử dụng để phân tích mối quan hệ tương quan giữa một số lượng lớn biến và để giải thích k biến ban đầu trong giới hạn m biến ít hơn. Điều này liên quan đến việc tìm cách cô đọng thông tin của k biến ban đầu thành một bộ m biến tiềm ẩn (hay là nhân tố), số nhân tố m phải nhỏ hơn số biến k (m < k) trong khi vẫn giữ lại cực đại lượng thông tin từ k biến ban đầu.
1. Phân tích nhân tố (Factor Analysis)
Có hai loại biến trong phân tích nhân tố là biến quan sát (biến đo lường, biến nghiên cứu hay mục hỏi trong thang đo) và biến tiềm ẩn. Biến quan sát là những biến được quy định hay mã hóa để dễ dàng cho quá trình phân tích nhân tố. Biến tiềm ẩn là những biến sau khi phân tích nhân tố khám phá có mối quan hệ tương quan với nhau và được nhóm lại với nhau tạo thành những biến mới mà sau này gọi là yếu tố hay nhân tố.
Phân tích nhân tố có hai dạng là Phân tích nhân tố khám phá EFA (Exploratory Factor Analyses) và Phân tích nhân tố khẳng định CFA (Confirmatory Factor Analyses). Phân tích nhân tố khám phá EFA có hai loại là phân tích yếu tố chính yếu PCA (Principal Components Analysis) và phân tích nhân tố chung FA (Common Factors Analysis hay Factor analysis) như Hình 1. Cả PCA và FA hầu như đều cho kết quả phân tích giống nhau. Phân tích nhân tố khám phá EFA dùng để xác định cấu trúc nhân tố, trong khi đó, phân tích nhân tố khẳng định CFA dùng để kiểm tra cấu trúc nhân tố. Phân tích yếu tố chính yếu PCA sẽ tạo nên một bức tranh về mối tương quan giữa những biến hữu ích (còn giữ lại sau khi phân tích nhân tố) trong việc xác định các nhân tố chung.
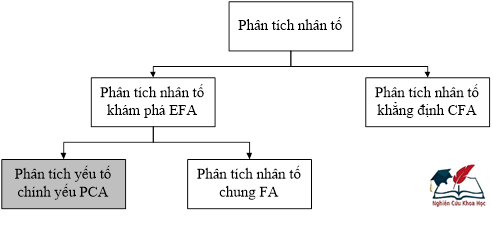
[Nguồn: nghiencuukhoahoc.edu.vn, 2017]
Hình 1. Các phương pháp phân tích nhân tố
Hình 2 trình bày quá trình phân tích nhân tố rút gọn cấu trúc dữ liệu. Từ ma trận dữ liệu cho đến ma trận tương quan giữa các biến và kết quả cuối cùng là ma trận nhân tố. Dữ liệu sau khi thu thập được mã hóa thành ma trận dữ liệu với k cột là k biến đo lường và n hàng là n quan sát (n: kích thước mẫu). Các biến có quan hệ tương quan với nhau được thể hiện thông qua hệ số tương quan và được thể hiện thành ma trận tương quan k hàng và k cột. Ma trận tương quan k biến thông qua phân tích nhân tố khám phá EFA rút gọn thành m nhân tố, trong đó, các nhân tố Fj có mối quan hệ với một số biến đo lường nhất định.
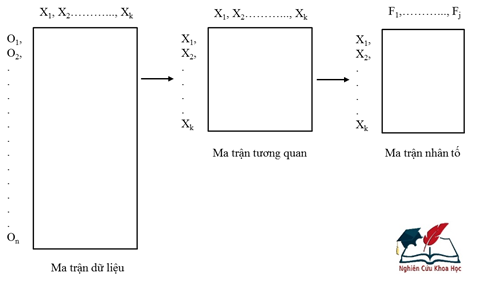
[Nguồn: nghiencuukhoahoc.edu.vn, 2017]
Hình 2. Quá trình rút gọn cấu trúc dữ liệu
2. Các giả định của phân tích nhân tố
Thứ nhất, tương quan. Phân tích nhân tố dựa trên nền tảng mối quan hệ giữa các biến nên các biến phải có mối tương quan với nhau. Nếu 20 biến đo lường không liên quan gì với nhau thì sẽ tạo ra 20 nhân tố, lúc này phân tích nhân tố trở nên vô nghĩa. Các biến không những tương quan với nhau mà còn phải có mối tương quan đủ mạnh thì phân tích nhân tố mới có ý nghĩa. Hay, các biến phải có một vài cấu trúc nhân tố tiềm ẩn bên dưới.
Thứ hai, mẫu phải đồng nhất, nghĩa là nhà nghiên cứu chọn mẫu phải có những đặc điểm tương đương nhau. Ví dụ, mẫu là những người của cùng một nền văn hóa hoặc sinh sống trong cùng một khu vực địa lý. Một mẫu đồng nhất có thể được lựa chọn đối với chỉ một biến nào đó. Ví dụ, nhà nghiên cứu chỉ quan tâm đến việc học tập của những người tham gia làm việc trong một ngành nghề nhất định, hoặc là trong một nhóm tuổi nhất định. Lấy mẫu đồng nhất có thể được sử dụng khi thực hiện lấy mẫu nhóm tập trung, vì các cá nhân nói chung thường thoải mái chia sẽ những suy nghĩ và ý tưởng của họ với các cá nhân khác, những người họ cho là giống với họ.
3. Quy trình phân tích nhân tố khám phá
Và trong phạm vi bài viết này, chúng tôi tập trung giới thiệu quy trình phân tích nhân tố khám phá EFA, đối với phân tích nhân tố khẳng định CFA sẽ được giới thiệu trong bài viết tiếp sau.
Theo dõi quy trình 5 bước phân tích nhân tố khám phá EFA ở Hình 3.
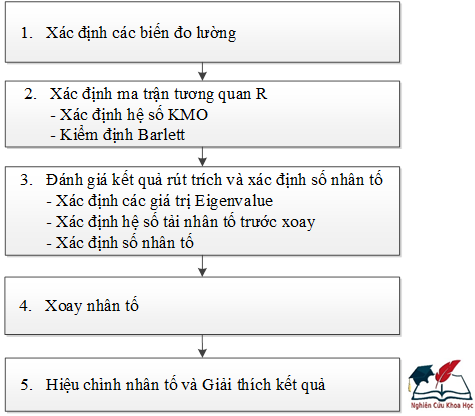
[Nguồn: nghiencuukhoahoc.edu.vn, 2017]
Hình 3. Quy trình phân tích nhân tố khám phá
Bước 1 - Xác định các biến đo lường. Nhà nghiên cứu lập bảng câu hỏi, xác định các biến đo lường và phân chúng vào các nhân tố phù hợp (Tham khảo bài viết QUY TRÌNH THIẾT KẾ BẢNG CÂU HỎI để nắm rõ các kỹ thuật nghiên cứu), còn việc xác định các biến đo lường và phân bổ chúng vào nhân tố nào thì phụ thuộc vào mục đích nghiên cứu và mô hình lý thuyết mà nhà nghiên cứu sử dụng khi xây dựng thang đo.
Bước 2 - Xác định ma trận tương quan R. Bộ dữ liệu nghiên cứu chính thức được sử dụng để tính toán hệ số tương quan và hình thành ma trận tương quan. Ma trận tương quan R được hình thành từ các hệ số tương quan tương ứng của các biến, ma trận tương quan R có kích thước kxk (với k là số biến nghiên cứu). Hệ số tương quan của hai biến x và y, kí hiệu là Cor(x,y) hay rxy, được tính bằng công thức sau.

Nếu cỡ mẫu càng lớn thì hệ số tương quan giữa các biến có xu hướng giảm nên cỡ mẫu lớn chưa hẳn đã tốt. Dù cỡ mẫu có như thế nào thì nếu hệ số tương quan giữa các biến không lớn hơn 0.30 thì phân tích nhân tố chưa chắc đã tin cậy. Tuy nhiên, mối tương quan giữa hai biến lớn không có nghĩa là tồn tại các yếu tố tiềm ẩn bên dưới, mà mối tương quan này còn phụ thuộc vào mức ảnh hưởng của các biến khác. Vì vậy, cần phải kiểm tra tương quan từng phần của các cặp biến khi có sự tác động của các biến khác (Tabachnick & Fidell, 2007) để đánh giá yếu tố tiềm ẩn.
Sử dụng hệ số Kaiser-Meyer-Olkin (KMO) để kiểm tra độ lớn của tương quan riêng phần. Hệ số này của một bộ số liệu phải đạt giá trị từ 0.50 đến 1.00 (KMO có trị từ 0.00 đến 1.00), được tính như sau.

Với rXiXj là hệ số tương quan giữa biến Xi và Xj,
aXiXj là hệ số tương quan riêng phần của Xi và Xj.
Nếu giá trị hệ số KMO của thang đo thuộc khoảng (0.00; 0.50) thì phân tích nhân tố EFA là không thích hợp vì tương quan riêng phần chiếm tỷ trọng lớn. Chúng ta còn có hệ số KMO của biến, nếu hệ số này của biến nhỏ hơn 0.50 thì biến đó nên được xem xét loại bỏ và nhà nghiên cứu thực hiện tính toán lại giá trị KMO. Sau khi loại biến, giá trị KMO có thể sẽ thay đổi theo hướng tích cực.
Tiếp đến là kiểm định Bartlett’s với giả thuyết H0: Hệ số tương quan của các biến trong ma trận tương quan bằng 0 (nghĩa là các biến không tương quan với nhau). Kiểm định Bartlett yêu cầu giá trị p-value hay Sig. < 0.05 (5%) để bác H0 hay nói cách khác các biến của ma trận tương quan R phải tương quan với nhau một cách có ý nghĩa ở độ tin cậy g = 95%.
Bước 3 - Đánh giá kết quả rút trích và xác định số nhân tố. Kết quả rút trích các biến phải có hệ số tải nhân tố (của một biến bất kì) tối thiểu là 0.50. Hệ số tải của một biến chỉ tải cao trên một nhân tố (không được tương đương với bất kì một nhân tố nào khác), số nhân tố sau khi được rút trích được xác định bằng nhiều tiêu chuẩn khác nhau.
Số nhân tố m phải nhỏ hơn (k - 1)/2.
Số nhân tố rút trích được xác định theo tiêu chuẩn Kaiser. Eigenvalue là phần phương sai được tính cho mỗi nhân tố, bằng tổng bình phương của những hệ số tải nhân tố. Nhân tố có giá trị Eigenvalue lớn hơn 1.00 thì được chọn vào mô hình. Theo tiêu chuẩn Kaiser thì số biến đo lường cần đạt được từ 20 đến 50 [Hair, et al., 1998], nhỏ hơn 20 biến thì quá ít và lớn hơn 50 thì quá nhiều. Lượng biến đo lường nên từ 40 trở lên và phần chung phải đạt khoảng 40% hay 0.40; cũng có thể sử dụng thang đo có từ 10 đến 30 biến nhưng phần chung phải đạt khoảng 0.70 hay 70% (Steven, 2002).
Người ta còn có thể dựa vào biểu đồ Scree, hoặc dựa vào phần trăm phương sai mà các yếu tố có thể giải thích được (tối thiểu là 50% phương sai các biến được giải thích bởi nhân tố chung) để quyết định số lượng nhân tố được rút trích (Bảng 1).
Bảng 1. Tiêu chuẩn chọn lựa nhân tố
|
Phương pháp |
Eigenvalue |
Biểu đồ Scree |
Phần trăm phương sai |
|
Tiêu chuẩn |
> 1.00 |
> 1.00 |
> 50% (hay 0.50) |
[Nguồn: nghiencuukhoahoc.edu.vn, 2017]
Việc đóng góp được nhiều phương sai vào nhân tố cũng có nghĩa rằng các biến đóng góp có hệ số tải cao trên một nhân tố, các biến này được điều chỉnh vì thường có hệ số tải cao trên một vài nhân tố thay vì tốt nhất là chỉ một nhân tố. Việc điều chỉnh này được gọi là xoay nhân tố để cấu trúc nhân tố đơn giản hơn, và giúp việc giải thích kết quả được dễ dàng hơn. Việc xoay nhân tố có thể được nhận thấy bằng đồ thị như quá trình xoay các trục mà mỗi trục đại diện cho một nhân tố (khái niệm trục ở đây được hiểu như trục x và y trong không gian hai chiều).
Việc quyết định số nhân tố còn phụ thuộc vào cách phân tích nhân tố, sẽ sử dụng phương pháp phân tích nhân tố chính yếu PCA (Principal Components Analysis). Mô hình phân tích nhân tố chính yếu không chứa những nhân tố đồng nhất: Tất cả phương sai của những biến quan sát được giả sử có thể rút trích thành những nhân tố chung vì phần chung ban đầu của mỗi biến bằng 1.00. Phân tích yếu tố chính yếu sử dụng tổng phương sai bao gồm phương sai phần chung Common, phương sai phần riêng Unique và phương sai sai số Error (Hình 4), trong đó:
- Phương sai phần chung là phần phương sai chung với tất cả các biến khác trong thang đo.
- Phương sai phần riêng là phần sai số của riêng biến đo lường, không được giải thích trong mối tương quan với các biến khác.
- Phương sai sai số là phần không giải thích bởi mối tương quan giữa các biến vì dữ liệu không tin cậy, sai số đo lường…

[Nguồn: nghiencuukhoahoc.edu.vn, 2017]
Hình 4. Phần chung, phần riêng và sai số
Bước 4 - Xoay nhân tố. Mục đích của việc xoay nhân tố nhằm tăng khả năng giải thích của các biến và làm cho cấu trúc nhân tố trở nên đơn giản. Có hai loại xoay nhân tố là xoay vuông góc và không vuông góc (Hình 5).

[Nguồn: nghiencuukhoahoc.edu.vn, 2017]
Hình 5. Các phép xoay nhân tố
Xoay vuông góc là phép xoay không phụ thuộc các nhân tố, vẫn giữ góc vuông giữa các trục nhân tố. Các phép xoay loại này gồm có Varimax, Quartimax, Equamax.
- Varimax là phép xoay cho phép trích nhiều phương sai nhất theo các biến đo lường, các biến sẽ có hệ số tải cao trên chỉ một vài yếu tố.
- Quartimax là phép xoay cho phép trích nhiều phương sai nhất theo các nhân tố, các biến sẽ có hệ số tải cao chỉ trên một nhân tố và thấp nhất đối với các nhân tố còn lại.
- Equamax là phép xoay kết hợp giữa hai kiểu quay trên.
Xoay không vuông góc phụ thuộc các nhân tố, góc giữa các trục nhân tố sau khi xoay không còn giữ nguyên góc vuông như ban đầu. Các phép xoay loại này gồm có Oblimin, Promax và Target matrix.
- Oblimin là phép xoay tối thiểu bình phương hệ số tải hiệp phương sai giữa các nhân tố.
- Promax là phép xoay đơn giản hóa cấu trúc trực giao bằng cách cực tiểu hệ số tải trên những nhân tố không đo lường hoặc thậm chí bằng 0.
- Target matrix với mục tiêu đơn giản cấu trúc nhân tố.
Cả hai loại phép xoay đều giữ nguyên giá trị phần riêng Uniquenesses như trước khi xoay, chỉ thay đổi trọng số nhân tố của biến đo lường đối với các nhân tố.
Từ ma trận nhân tố, nhà nghiên cứu có thể tính toán các hệ số tương quan giữa các biến đo lường theo tổng của tích các hệ số tải tương ứng với các nhân tố được rút trích bằng công thức sau.

Bước 5 - Giải thích kết quả và hiệu chỉnh nhân tố. Quá trình phân tích có thể lặp đi lặp lại vài lần trước khi có kết quả cuối cùng. Nếu bất kì biến nào không thỏa mãn các yêu cầu thì được xem xét và loại ra khỏi thang đo trước khi lặp lại quá trình phân tích. Nếu các hệ số và tiêu chuẩn đều đạt yêu cầu thì kết quả được giải thích thông qua các phần chung Communalities, hệ số tương quan, hệ số tải nhân tố trong ma trận xoay nhân tố (Rotated Factor Matrix), hệ số KMO, tổng phương sai trích (Total Variance Explained).
Việc hiệu chỉnh nhân tố phụ thuộc nội dung của các biến (câu hỏi) sau khi nhóm theo nhân tố mới. Nhà nghiên cứu đánh giá, quyết định đặt lại tên cho nhân tố mới hay quyết định vẫn giữ nguyên các thành phần theo giả thuyết ban đầu.
4. Đánh giá kết quả phân tích nhân tố
Hai giá trị quan trọng cần phải kiểm tra thông qua phân tích nhân tố EFA là giá trị hội tụ và giá trị phân biệt. Thang đo đạt giá trị hội tụ khi các biến trong cùng một nhân tố có hệ số tải nhân tố cao trên nhân tố đó và thấp trên các nhân tố còn lại. Điều đó có nghĩa là hệ số tải của biến lên nhân tố sau khi xoay phải đạt giá trị tối thiểu là 0.50. Nếu hệ số tải nhỏ hơn 0.50 thì nhà nghiên cứu nên xem xét loại biến đó ra khỏi thang đo.
Tiếp theo là dựa vào sự chênh lệch đại số hệ số tải giữa các biến, nếu  (trị tuyệt đối của hiệu hai hệ số tải lớn hơn 0.20) thì được chấp nhận nhưng nếu ngược lại thì biến Xi có hệ số tải trên nhân tố F1 và F2 gần như nhau, nghĩa là nó không đo lường cụ thể một nhân tố (một biến đo lường tốt có hệ số tải cao trên nhân tố này nhưng thấp trên các nhân tố còn lại). Các biến không thỏa điều kiện này cũng phải được xem xét để loại ra khỏi thang đo.
(trị tuyệt đối của hiệu hai hệ số tải lớn hơn 0.20) thì được chấp nhận nhưng nếu ngược lại thì biến Xi có hệ số tải trên nhân tố F1 và F2 gần như nhau, nghĩa là nó không đo lường cụ thể một nhân tố (một biến đo lường tốt có hệ số tải cao trên nhân tố này nhưng thấp trên các nhân tố còn lại). Các biến không thỏa điều kiện này cũng phải được xem xét để loại ra khỏi thang đo.
Đối với giá trị hội tụ thì phân tích nhân tố chính yếu PCA thường có tổng phương sai trích lớn hơn phân tích nhân tố chung FA vì mục đích của PCA là rút trích được nhiều phương sai nhất. Chú ý là nếu các biến không thỏa mãn các yêu cầu hội tụ như trên thì sau khi xem xét loại bỏ các biến ra khỏi thang đo thì phải tiến hành phân tích nhân tố EFA lại toàn bộ thang đo để đánh giá kết quả.
Thang đo đạt giá trị phân biệt khi phân tích nhân tố EFA trích được lượng nhân tố phù hợp với giả thuyết nghiên cứu, nghĩa là số lượng nhân tố trong nghiên cứu chính thức và số lượng nhân tố sau khi được rút trích thông qua phân tích nhân tố EFA là giống nhau về số lượng và có thành phần không thay đổi nhiều.
Khi số lượng nhân tố trích không phù hợp: Lớn hơn hoặc nhỏ hơn số nhân tố của giả thuyết ban đầu. Nếu nhỏ hơn, nghĩa là có một vài nhân tố được gộp chung với các nhân tố khác, các nhân tố được gộp này có thể có một vài điểm chung với các nhân tố khác hoặc thực chất các nhân tố này là một nhưng giả thuyết lại phân thành các nhân tố khác nhau. Nếu lớn hơn thì theo giả thuyết chỉ là một nhân tố nhưng kết quả phân tích phân thành nhiều nhân tố hoặc gộp các biến của nhân tố này vào chung với các nhân tố khác. Xảy ra hai trường hợp trên có thể do:
- Lý thuyết xây dựng không phù hợp;
- Nhà nghiên cứu vấn đề chưa thấu đáo;
- Áp dụng lý thuyết của thị trường này cho thị trường khác mà chưa điều chỉnh cho phù hợp;
- Có thể khái niệm nghiên cứu ở thị trường này là đơn hướng nhưng ở thị trường khác là đa hướng hoặc ngược lại nhưng nhà nghiên cứu chưa nhận ra;
- Hoặc có thể do các nguyên nhân về bộ dữ liệu thu thập không chính xác và không được kiểm tra cẩn thận, chưa lọc nhiễu và làm sạch bộ dữ liệu.
Sau khi có được kết quả phân nhóm, phần mềm SPSS tự động tạo ra điểm nhân tố (nếu mục đích cho phân tích hồi quy) ký hiệu là FAC1_1, FAC2_1, FAC3_1… cho lần phân tích nhân tố EFA thứ nhất và FAC1_2, FAC2_2, FAC3_2… cho lần phân tích nhân tố EFA thứ hai, và tương tự cho các lần phân tích sau.
Việc cuối cùng cần làm là đặt lại tên nhân tố cho các biến nếu các biến không được gộp lại đúng như giả thuyết ban đầu. Tên biến cũng là một phần quan trọng để quản lý các biến thông qua các nhân tố được hiệu quả. Việc đặt tên biến phụ thuộc vào quan điểm của từng nhà nghiên cứu, nhưng cần kiểm tra kĩ lưỡng nội dung của các biến sau khi phân tích nhân tố EFA để đặt tên nhân tố cho phù hợp với thực tế nghiên cứu.
Tài liệu tham khảo
- Hair, J. F. Jr, Anderson, R-E, Tatham, R. L., & Black, W. C. (1998). Multivariate Data Analysis, (5th Edition), Prentice Hall.
- Tabachnick, B. G., & Fidell, L. S. (2007). Using multivariate statistics. Boston: Pearson/Allyn & Bacon.
Kết thúc.
Lý thuyết Phân tích nhân tố khám phá EFA trình bày trên đây trong có vẻ rất phức tạp, trong khi lý thuyết Phân tích độ tin cậy thang đo (với hệ số Cronbach’s Alpha) có phần đơn giản hơn, đây là 2 kỹ thuật phổ biến nhất để kiểm định thang đo mà bạn không thể bỏ qua.
Và để có thể vận dụng, thực hành và đánh giá kết quả kiểm định một cách linh hoạt mà không vấp phải những sai lầm đáng kể thì Chương 4 cuốn sách NGHIÊN CỨU KHOA HỌC TRONG KINH TẾ - XÃ HỘI & Hướng dẫn viết luận văn/luận án 2023 sẽ trang bị cho bạn đầy đủ các kỹ năng cần thiết. Tham khảo để thấy cách bạn sẽ được sở hữu một sản phẩm chất lượng thuộc Top 100 sản phẩm Phân tích kinh tế bán chạy của tháng tại Fahasa.com.
Tin tức liên quan

27/02
2023
Đánh giá thang đo nghiên cứu thông qua độ tin cậy và các giá trị nội dung (và tính đơn hướng), giá trị hội tụ, giá trị phân biệt và giá trị liên hệ lý thuyết.

02/03
2023
Thông thường, Mô hình nhân tố khẳng định CFA là tiền thân cho Mô hình cấu trúc tuyến tính SEM trong việc chỉ định các mối quan hệ cấu trúc (như hồi quy) của các biến tiềm ẩn, nghĩa là CFA được thực hiện trước và sau đó kết quả là đầu vào cho SEM.

30/10
2023
Thông thường, mọi người thường nghĩ đạo văn là vấn đề sao chép tác phẩm hoặc mượn ý tưởng của người khác, nhưng nếu chỉ "sao chép" và "mượn" thì chưa đủ để nói lên tính nghiêm trọng của vấn đề.
Xem thêm